1. What is database?
A database is an organized collection of data, stored and retrieved digitally from a remote or local computer system.
2. Datatype of MSSQ?
Numeric Types:
- INT: Integer data type.
- DECIMAL or NUMERIC: Fixed-point numeric data type.
- FLOAT: Floating-point numeric data type.
Character and String Types:
- CHAR: Fixed-length character data type.
- VARCHAR: Variable-length character data type.
- TEXT: Variable-length character data type for large text.
Date and Time Types:
- DATE: Date data type.
- TIME: Time data type.
- DATETIME: Date and time data type.
- SMALLDATETIME: Compact date and time data type.
Binary Types:
- BINARY: Fixed-length binary data type.
- VARBINARY: Variable-length binary data type.
- IMAGE: Variable-length binary data type for large binary data.
Miscellaneous Types:
- BIT: Boolean data type.
- UNIQUEIDENTIFIER: Unique identifier (GUID) data type.
- XML: XML data type.
Row Versioning Types:
- TIMESTAMP (deprecated, replaced by ROWVERSION): Automatic unique binary numbers for versioning.
Large Object Types:
- NTEXT: Variable-length Unicode character data type for large text.
- NCHAR: Fixed-length Unicode character data type.
- NVARCHAR: Variable-length Unicode character data type.
- BLOB: Binary large object data type.
3. What is DBMS?
DBMS stands for Database Management System. DBMS is a system software responsible for the creation, retrieval, updation, and management of the database. It ensures that our data is consistent, organized, and is easily accessible by serving as an interface between the database and its end-users or application software.
- It helps maintain data uniformity
- Handles large sets of data efficiently (দক্ষতার সাথে)
- Versatile (বহুমুখী)
- Faster way of managing data
4. What is RDBMS?
RDBMS stands for Relational Database Management System.
- Allow multiple-user access
- Store large packs of data
- Minimum Data Redundancy (অপ্রয়োজনীয়তা)
- Maintains Data Integration (মিশ্রণ)
- Better Tools for Structuring and Organizing Data
5. How is it different from DBMS?
The key difference here, compared to DBMS, is that RDBMS stores data in the form of a collection of tables, and relations can be defined between the common fields of these tables. Most modern database management systems like MySQL, Microsoft SQL Server, Oracle, IBM DB2, and Amazon Redshift are based on RDBMS.
- RDBMS is the improved version of DBMS, and therefore, faster and more efficient than DBMS.
- Use DBMS for basic data storage and retrieval; use RDBMS when you need structured data with relationships and want to enforce data integrity through features like transactions and ACID properties.
| Parameter | DBMS | RDBMS |
|---|---|---|
| Function | DBMS is system software for creating, storing, managing, updating and retrieving data from databases. | RDBMS is software that allows the creation and management of databases in a tabular format for efficient retrieval, updation, and storage of data. |
| Storage | In DBMS, the storage of data is in the files. It is arranged either in a hierarchical form or navigational form. | In RDBMS, the data is stored in tables. There is no hierarchy and instead, follow a relational model. Columns are the headers and rows contain the corresponding values. |
| Number of Users | Database Management System can only support a single user. | Relational Database Management System allows access to multiple users to the databases. |
| Normalization (organizing data in the database) | DBMS does not support normalization. | Normalization is enabled in RDBMS. In fact, it was introduced by Edgar F. Codd for his relational database model. |
| Data Type | DBMS cannot store large quantities of data. | RDBMS allows users to store a large set of data. |
| Data Relationships | In the database management system, there are no relationships amongst the data stored. | In RDBMS, there are relationships formed amongst the data stored in tables. |
| Data Fetching | The process of data fetching in DBMS is slow. | The process of Data Fetching is faster, and efficient in RDBMS because of its relational model. |
| Distributed Databases | DBMS does not support the distribution of databases. A distributed database is a database that can be stored at different locations. | RDBMS supports distributed databases. |
| Data Redundancy | The version of DBMS increases data redundancy (repetition of data). | In RDBMS, data redundancy is eliminated that reduces wastage of time and resources. |
| Hardware and Software Requirements | DBMS needs minimum software and hardware requirements. | In RDBMS, hardware and software requirements are higher than the classic DBMS. |
| Data Integrity | Database Management System does not support any data integration constraints or methods. | The Relational Database Management System supports data integrity constraints. |
| Data Access | In DBMS, you can access only a single file from a single database. | In RDBMS, you can access multiple data at a single time. |
| Data Security | DBMS is more prone to data theft, and access to unauthorized users because it does not allow any data security measures. | RDBMS supports security measures and is more secure than the traditional RDBMS. |
| ACID Properties | DBMS does not support any ACID properties. | RDBMS supports ACID properties and ensures no data inconsistencies. |
| Data Client-Server | DBMS does not support client-server architecture. | RDBMS supports client-server architecture |
| Examples | XML, File systems, window registry, etc are some examples of database management systems. | Oracle, MYSQL, SQL Server, etc are some of the examples of Relational Database Management Systems. |
6. What is SQL?
SQL stands for Structured Query Language. It is the standard language for relational database management systems.
7. What are Tables and Fields?
A table is an organized collection of data stored in the form of rows and columns. Columns can be categorized as vertical and rows as horizontal. The columns in a table are called fields while the rows can be referred to as records.
8. What are Constraints in SQL?
Constraints are used to specify the rules concerning data in the table. It can be applied for single or multiple fields in an SQL table during the creation of the table or after creating using the ALTER TABLE command. The constraints are:
- NOT NULL - Restricts NULL value from being inserted into a column.
- CHECK - Verifies that all values in a field satisfy a condition.
- DEFAULT - Automatically assigns a default value if no value has been specified for the field.
- UNIQUE - Ensures unique values to be inserted into the field.
- INDEX - Indexes a field providing faster retrieval of records.
- PRIMARY KEY - Uniquely identifies each record in a table.
- FOREIGN KEY - Ensures referential integrity for a record in another table.
9. What is a Primary Key?
The PRIMARY KEY constraint uniquely identifies each row in a table. It must contain UNIQUE values and has an implicit NOT NULL constraint.
10. What is a UNIQUE constraint?
A UNIQUE constraint ensures that all values in a column are different. This provides uniqueness for the column(s) and helps identify each row uniquely. Unlike primary key, there can be multiple unique constraints defined per table. The code syntax for UNIQUE is quite similar to that of PRIMARY KEY and can be used interchangeably.
| Attribute | Primary Key | Unique Key |
|---|---|---|
| Uniqueness | Yes, and it must be unique for each record. | Yes, but uniqueness is not always mandatory. |
| NULL values | No, primary key values cannot be NULL. | Yes, unique key values can be NULL. |
| Number per Table | One per table. | Multiple unique keys can exist in a table. |
| Purpose | Main identifier for the table. | Ensures uniqueness but not always the main identifier. |
| Constraints | Implies uniqueness, non-null, and integrity constraints. | Imposes uniqueness but may allow NULL values. |
11. What is a Foreign Key?
A FOREIGN KEY comprises of single or collection of fields in a table that essentially refers to the PRIMARY KEY in another table. Foreign key constraint ensures referential integrity in the relation between two tables.
12. What is a Join? List its different types.
The SQL Join clause is used to combine records from two or more tables in a SQL database based on a related column between the two.
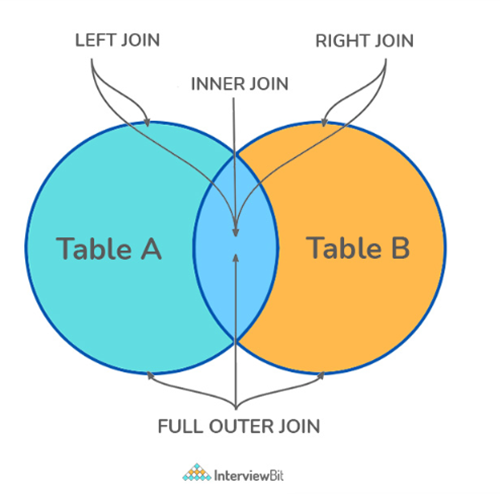
There are four different types of JOINs in SQL:
- (INNER) JOIN: Retrieves records that have matching values in both tables involved in the join.
SELECT * FROM Table_A JOIN Table_B;
SELECT * FROM Table_A INNER JOIN Table_B;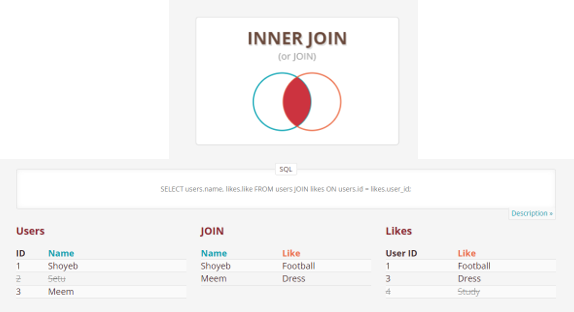
- LEFT (OUTER) JOIN: Retrieves all the records/rows from the left and the matched records/rows from the right table.
SELECT * FROM Table_A A LEFT JOIN Table_B B ON A.col = B.col;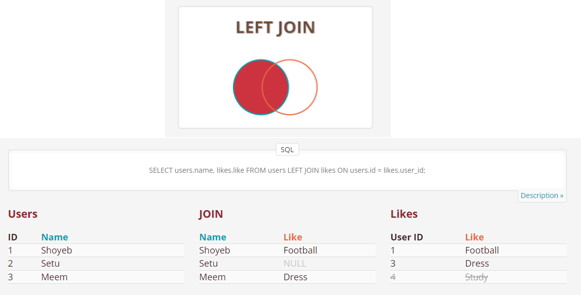
- RIGHT (OUTER) JOIN: Retrieves all the records/rows from the right and the matched records/rows from the left table.
SELECT * FROM Table_A A RIGHT JOIN Table_B B ON A.col = B.col;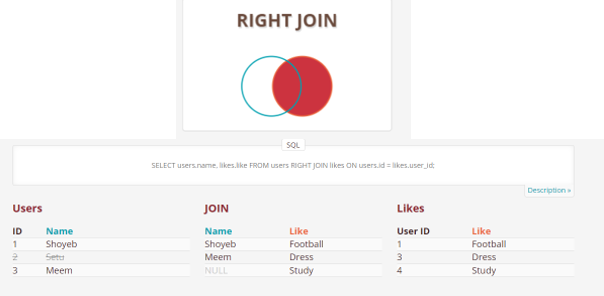
- FULL (OUTER) JOIN: Retrieves all the records where there is a match in either the left or right table.
SELECT * FROM Table_A A FULL JOIN Table_B B ON A.col = B.col;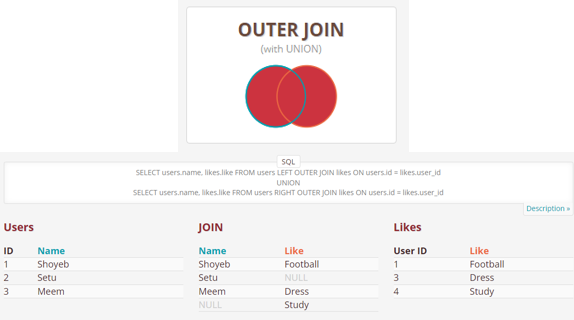
There are also two joins available:
13. What are some common clauses used with SELECT query in SQL?
Some common SQL clauses used in conjunction with a SELECT query are as follows:
- WHERE clause in SQL is used to filter records that are necessary, based on specific conditions.
- ORDER BY clause in SQL is used to sort the records based on some field(s) in ascending (ASC) or descending order (DESC).
- GROUP BY clause in SQL is used to group records with identical data and can be used in conjunction with some aggregation functions to produce summarized results from the database.
- HAVING clause in SQL is used to filter records in combination with the GROUP BY clause. It is different from WHERE, since the WHERE clause cannot filter aggregated records.
14. What is an Alias (উপনাম) in SQL?
An alias is a feature of SQL that is supported by most, if not all, RDBMSs. It is a temporary name assigned to the table or table column for the purpose of a particular SQL query. In addition, aliasing can be employed as an obfuscation technique to secure the real names of database fields. A table alias is also called a correlation name.
15. Index in SQL:
A database structure that enhances data retrieval efficiency by providing a quick lookup of rows based on the values in one or more columns.
16. Clustered Index:
A type of index that determines the physical order of data rows in the table, and the table can have only one; it directly affects the order of data storage.
17. Non-Clustered Index:
A type of index that does not alter the physical order of data rows and creates a separate structure for quick data retrieval without changing the actual data storage order.
Normalization:
ধরুন আপনি একটা কোনো ওয়েব সিস্টেম বানাচ্ছেন আর তার জন্য ডাটাবেস স্ট্রাকচার বানিয়েছেন, কিন্তু সেটাকে normalised বানাননি, ফলে দেখবেন খুব কম ডাটা এন্ট্রি করার পরেই অনেক জায়গা ইউজ হয়ে গেছে। আবার ডাটাবেস টা localhost থেকে খুলে দেখতে পারবেন যে কিছু কিছু জায়গায় একই ফিল্ড বার বার ব্যবহার হয়েছে, ফলে সেটা অনেক ডিস্ক স্পেস নষ্ট করেছে আবার ডাটা গুলো বিভিন্ন টেবিলের মধ্যে এদিকে ওদিকে ছড়িয়ে আছে মানে ইন্টেগ্রিটি নেই বললেই চলে। তাই যখনই আমরা ডাটাবেস বানাই তখন একটা পদ্ধতি অনুসরণ করি যাতে সেই ডাটাবেস টা অনেক বেশি অপটিমাইজ ও ইন্টিগ্রেটেড(একসাথে জুড়ে থাকার ক্ষমতা) ও সবথেকে কম রিডানডেন্সি(dublicate) রাখার দিক টা মাথায় রেখে। Database normalisation হলো database কে সব থেকে বেশি dublicate ভ্যালু এর থেকে মুক্ত রাখা, আর এটা করা হয় একই ডাটাবেসের অনেক টেবিলের মধ্যে একটা কমন ফিল্ড/কলাম এর মধ্যে রেলেশনশিপ established করে সব টেবিলের dublicate ভালুগুলোকে ম্যাক্সিমাম কম করে। এই normalisation প্রসেস একমাত্র স্ট্রাকচার ডাটাবেসের ক্ষেত্রেই প্রযোজ্য। Normalisation কিন্তু কখনোই 100% রাখা সম্ভব না। Normalisation এর ক্ষেত্রে 6 টি নর্মালিসেশন আছে।
- 1NF (1st normalisation form)
- 2NF
- 3NF
- BCNF/3.5 NF (boyce-codd normal form)
- 5NF
- 6NF এবার আমরা নর্মালাইজেশন যখনই একটা একটা করে ধাপে ধাপে এগিয়ে যাই ততই আমাদের ডাটাবেস তত বেশি ঐক্যবদ্ধ ভাবে থাকে। নর্মালিসেশনের মাধ্যমে একটা ডাটাবেসের আন্ডার এ একাধিক টেবিলের মধ্যে যদি একই ফিল্ড কমন থাকে তাহলে বার বার আপনাকে তার জন্য একই ডাটা ইনপুট করতে হবেনা, আবার যদি অনেক বড় সিস্টেমে 2 তো টেবিলের মধ্যে একই ডাটা ফিল্ড থাকলে 2 তো টেবিলের জন্য আলাদা আলাদা ডাটা ইনপুট করা যায়না। ফলে একই ডাটা একটা ফিল্ড এর জন্য সেন্ট্রালাইজড ভাবে থাকতে পারে। যত বেশি normalised ফর্ম এর উপরের দিকে ওঠা যাবে তত বেশি রিডানডেন্সি কম হবে। নরমালি আমাদের BCNF অব্দি গেলেই অনেকটা ঠিক থাকে।
18. What are the various forms of Normalization?
Normal Forms are used to eliminate or reduce redundancy in database tables. The different forms are as follows:
Students Table:
| Student | Address | Books Issued | Salutation |
|---|---|---|---|
| Sara | Amanora Park Town 94 | Until the Day I Die (Emily Carpenter), Inception (Christopher Nolan) | Ms. |
| Ansh | 62nd Sector A-10 | The Alchemist (Paulo Coelho), Inferno (Dan Brown) | Mr. |
| Sara | 24th Street Park Avenue | Beautiful Bad (Annie Ward), Woman 99 (Greer Macallister) | Mrs. |
| Ansh | Windsor Street 777 | Dracula (Bram Stoker) | Mr. |
Students Table (1st Normal Form)
| Student | Address | Books Issued | Salutation |
|---|---|---|---|
| Sara | Amanora Park Town 94 | Until the Day I Die (Emily Carpenter) | Ms. |
| Sara | Amanora Park Town 94 | Inception (Christopher Nolan) | Ms. |
| Ansh | 62nd Sector A-10 | The Alchemist (Paulo Coelho) | Mr. |
| Ansh | 62nd Sector A-10 | Inferno (Dan Brown) | Mr. |
| Sara | 24th Street Park Avenue | Beautiful Bad (Annie Ward) | Mrs. |
| Sara | 24th Street Park Avenue | Woman 99 (Greer Macallister) | Mrs. |
| Ansh | Windsor Street 777 | Dracula (Bram Stoker) | Mr. |
Students Table (2nd Normal Form)
| Student_ID | Student | Address | Salutation |
|---|---|---|---|
| 1 | Sara | Amanora Park Town 94 | Ms. |
| 2 | Ansh | 62nd Sector A-10 | Mr. |
| 3 | Sara | 24th Street Park Avenue | Mrs. |
| 4 | Ansh | Windsor Street 777 | Mr. |
Books Table (2nd Normal Form)
| Student_ID | Book Issued |
|---|---|
| 1 | Until the Day I Die (Emily Carpenter) |
| 1 | Inception (Christopher Nolan) |
| 2 | The Alchemist (Paulo Coelho) |
| 2 | Inferno (Dan Brown) |
| 3 | Beautiful Bad (Annie Ward) |
| 3 | Woman 99 (Greer Macallister) |
| 4 | Dracula (Bram Stoker) |
Students Table (3rd Normal Form)
| Student_ID | Student | Address | Salutation_ID |
|---|---|---|---|
| 1 | Sara | Amanora Park Town 94 | 1 |
| 2 | Ansh | 62nd Sector A-10 | 2 |
| 3 | Sara | 24th Street Park Avenue | 3 |
| 4 | Ansh | Windsor Street 777 | 1 |
Books Table (3rd Normal Form)
| Student_ID | Book Issued |
|---|---|
| 1 | Until the Day I Die (Emily Carpenter) |
| 1 | Inception (Christopher Nolan) |
| 2 | The Alchemist (Paulo Coelho) |
| 2 | Inferno (Dan Brown) |
| 3 | Beautiful Bad (Annie Ward) |
| 3 | Woman 99 (Greer Macallister) |
| 4 | Dracula (Bram Stoker) |
Salutations Table (3rd Normal Form)
| Salutation_ID | Salutation |
|---|---|
| 1 | Ms. |
| 2 | Mr. |
| 3 | Mrs. |
19. What are Aggregate and Scalar functions?
An aggregate function performs operations on a collection of values to return a single scalar value. Aggregate functions are often used with the GROUP BY and HAVING clauses of the SELECT statement. Following are the widely used SQL aggregate functions:
- AVG() - Calculates the mean of a collection of values.
- COUNT() - Counts the total number of records in a specific table or view.
- MIN() - Calculates the minimum of a collection of values.
- MAX() - Calculates the maximum of a collection of values.
- SUM() - Calculates the sum of a collection of values.
- FIRST() - Fetches the first element in a collection of values.
- LAST() - Fetches the last element in a collection of values.
Note: All aggregate functions described above ignore NULL values except for the COUNT function.
A scalar function returns a single value based on the input value. Following are the widely used SQL scalar functions:
- LEN() - Calculates the total length of the given field (column).
- UCASE() - Converts a collection of string values to uppercase characters.
- LCASE() - Converts a collection of string values to lowercase characters.
- MID() - Extracts substrings from a collection of string values in a table.
- CONCAT() - Concatenates two or more strings.
- RAND() - Generates a random collection of numbers of a given length.
- ROUND() - Calculates the round-off integer value for a numeric field (or decimal point values).
- NOW() - Returns the current date & time.
- FORMAT() - Sets the format to display a collection of values.
20. What is a Stored Procedure?
A stored procedure is a subroutine available to applications that access a relational database management system (RDBMS). Such procedures are stored in the database data dictionary. The sole disadvantage of stored procedure is that it can be executed nowhere except in the database and occupies more memory in the database server. It also provides a sense of security and functionality as users who can’t access the data directly can be granted access via stored procedures.
DELIMITER $$
CREATE PROCEDURE FetchAllStudents()
BEGIN
SELECT * FROM myDB.students;
END $$
DELIMITER ;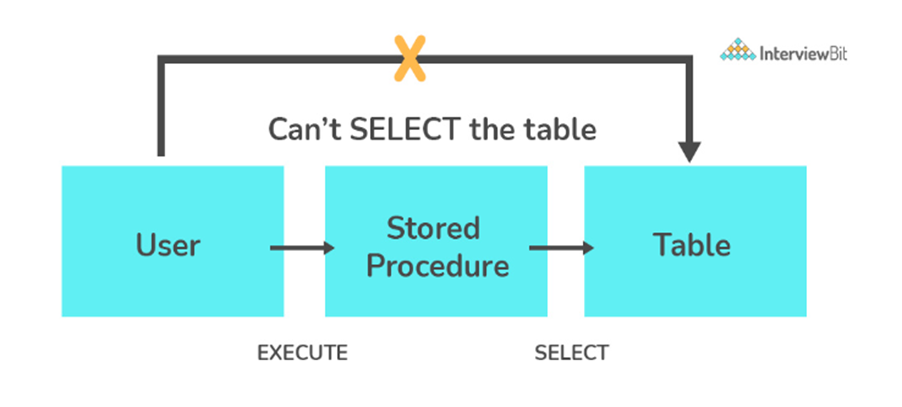
SQL Query
Interview Question (OSL):
- Find out count, name and age from list where age >= 25 AND age ⇐ 26
SELECT COUNT(*) AS Count,
Name,
Age
FROM YourTableName
WHERE Age >= 25 AND Age <= 26
GROUP BY Name, Age;Interview Question (ASD):
- You have two tables (EmployeeInfo and Salary). Now joining the two tables and get employee info whose salary is maximum.
1. EmployeeInfo
- a. Id
- b. EmployeeId
- c. EmployeeName
- d. Designation
- e. Department
- f. DateOfJoin
2. Salary
- a. Id
- b. EmployeeInfoId (Foreign Key)
- c. Salary
SELECT e.EmployeeId,
e.EmployeeName,
e.Designation,
e.Department,
e.DateOfJoin,
s.Salary
FROM EmployeeInfo e
JOIN Salary s ON e.Id = s.EmployeeInfoId
WHERE s.salary = (SELECT MAX(salary) FROM Salary);Visit here to get more queries: W3Schools SQL
SQL Statements
- Create table
CREATE TABLE table_name (col_1 datatype,
col_2 datatype,
col_3 datatype);- Update
UPDATE table_name
SET col_1 = value_1, column_2 = value_2
WHERE condition;- Insert
INSERT INTO table_name (column1, column2, column3, ...)
VALUES (value1, value2, value3, ...);- Delete table
DROP TABLE table_name;
- Sort
SELECT * FROM table_name
ORDER BY col_1;
SELECT * FROM table_name
ORDER BY col_1 DESC, col_3, col_6 DESC;- Count
SELECT COUNT(*) FROM Students;
SELECT COUNT(Id) FROM Students WHERE Roll BETWEEN 2 AND 5;
SELECT Roll, Name
FROM Students
WHERE Roll BETWEEN 5 AND 17;Others:
- District
SELECT DISTINCT Name FROM Students;- And + Or
SELECT * FROM Students
WHERE Roll BETWEEN 6 AND 10 AND (Name LIKE 'R%' OR Name LIKE 'M%');- MAX
SELECT MAX(Roll)
FROM Students;- MIN
SELECT MIN(Roll)
FROM Students;-
SUM(), AVG() as like as MIN(), MAX()
-
Case
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
WHEN conditionN THEN resultN
ELSE result
END;- ANY
SELECT ProductName
FROM Products
WHERE ProductID = ANY
(SELECT ProductID
FROM OrderDetails
WHERE Quantity > 1000);- ALL
SELECT ProductName
FROM Products
WHERE ProductID = ALL
(SELECT ProductID
FROM OrderDetails
WHERE Quantity = 10);GROUP BY and HAVING
GROUP BY and HAVING are clauses in SQL that are often used together, but they serve different purposes in a query.
1. GROUP BY:
ধরি একই নামের দেশে ৩-৪ জন এম্পয়ি আছে। নিচের এই কুয়েরি প্রিন্ট করলে বাংলাদেশের ৩ জন ও দেশের নাম, ভারতের ৬ জন ও দেশের নাম এইভাবে গ্রুপ করে প্রিন্ট করবে। চাইলে count এর বদলে Sql function like: COUNT(), MAX(), MIN(), SUM(), AVG() ইউজ করতে পারি,
- The
GROUP BYclause is used to group rows based on the values in one or more columns. - It is typically used with aggregate functions (e.g., COUNT, SUM, AVG) to perform calculations on each group of rows.
Example:
SELECT COUNT(CustomerID), Country
FROM Customers
GROUP BY Country;- In this example, rows are grouped by the “department” column, and the
COUNT(*)function calculates the number of employees in each department.
2. HAVING:
এটাও গ্রুপের সাথেই ইউজ হয়ে কিন্তু আরেকটি কন্ডিশন দিয়ে দেয় যে এমন কিছু থাকতে হবে।
- The
HAVINGclause is used to filter the results of aGROUP BYquery based on a specified condition. - It is applied after the
GROUP BYand aggregate functions in order to filter groups that meet certain criteria.
Example:
SELECT COUNT(CustomerID), Country
FROM Customers
GROUP BY Country
HAVING COUNT(CustomerID) > 5;- In this example, rows are grouped by the “department” column, and the
HAVINGclause filters the results to include only those groups where the average salary is greater than 50,000.
Summary:
In summary, GROUP BY is used to group rows based on certain columns, and aggregate functions are often applied to these groups. The HAVING clause is then used to filter the grouped results based on conditions involving the aggregated values.
Store Procedure
What is a Stored Procedure?
A stored procedure is a prepared SQL code that you can save, so the code can be reused over and over again. So if you have an SQL query that you write over and over again, save it as a stored procedure, and then just call it to execute it. You can also pass parameters to a stored procedure, so that the stored procedure can act based on the parameter value(s) that is passed.
Store procedure: (Single parameter)
CREATE PROCEDURE SelectAllCustomers @City nvarchar(30)
AS
SELECT * FROM Customers WHERE City = @City
GO;
EXEC SelectAllCustomers @City = 'London';Store procedure: (Multiple parameter)
CREATE PROCEDURE SelectAllCustomers @City nvarchar(30), @PostalCode nvarchar(10)
AS
SELECT * FROM Customers WHERE City = @City AND PostalCode = @PostalCode
GO;
EXEC SelectAllCustomers @City = 'London', @PostalCode = 'WA1 1DP';SQL Cursor
Visit here to get advanced details: What is Cursor in SQL
While loop using cursor:
DECLARE @id INT = 1;
WHILE @id <= (SELECT MAX(id) FROM employees)
BEGIN
UPDATE employees
SET salary = salary * 1.1
WHERE id = @id;
SET @id = @id + 1;
END;